What the heck is a reverse proxy!
Around the time when I was learning to tread the waters of web development, I had started with PHP as my trusty language of choice. I’m not going to nitpick on PHP today, but one thing I had taken for granted until moved out of it, was the Apache2, the good ole’ reliable. I had assumed that all VPS machines - from hobby to production-grade ones, had a sturdy Apache server running and gracefully serving your web stuff. So in an ideal world, you’d build wonderful applications, put it in the /var/www/html directory of your host machine, and Apache2 would serve it while you got ready for breakfast.
Rinse and repeat.
I guess if I had started with Ruby, I’d probably have developed similar notions, because from what I’ve heard, deploying Ruby applications is scary and difficult. Adding to this is Ruby’s GIL (Global Interpreter Lock). If you are unfamiliar with Ruby, it means that only one Ruby process can access the interpreter at time, so multi-threading is not exactly parallel and concurrent, but more of context switching between threads, which means only one request (per thread) can access a CPU core at a time. To say the least, it doesn’t translate to performance. You’d be better off lending the serve my app, thank you very much part to something mature, like for instance, Apache.
Throw in a couple of more updates from PHP and I’m using Laravel now and responsible for deployment as well. I’d google “How to deploy Laravel” and the first Digital Ocean article would pop up with the customary suffix in the title “..with Nginx”. Reading those articles, I’d come across the term “proxy” or “reverse proxy” over and over again. So what the heck does it mean?
Wait, a server serving a server?
Unlike old PHP static sites, there was no more dropping off the files in the DocumentRoot and assumed they’d be served. Laravel could run its server with php artisan serve, (making the A in LAMP stack irrelevant for development at least). Bind it with the 0.0.0.0 and you could access your app from the internet using IPV4 address.
But what if you had to run multiple applications on the host, each to be identified by its route, domain, or subdomain. That’s something Apache or Nginx servers were good at. You could be running a bunch of apps in the same network and they’d take care of routing the requests for you. You defined the rules in configuration files and Nginx/Apache read those rules for each domain. Want SSL for a httpsrockz.com? Check. Block an IP from accessing your site? Got that covered.
Apache/Nginx, they sit in front of your apps and take in all requests from the outside world and “proxy” them from and to your apps running on the host machine. This is basically what a “reverse proxy” does. It sits inside a private network and directs the incoming requests to the app of choice.
Before we go any further, you should know the proxy server is a board term. There are are many kinds of proxy servers (most of them are used interchangeably), but the two main ones encountered in the wild are the forward proxy and the reverse proxy. It’s a tad bit confusing because on a high level both appear to perform the same thing - proxy requests. But like we discussed, if we can look at where they sit on the network-side of things, we’ll get an idea of how to differentiate them with nothing but our Jedi skills.
This is how a forward proxy looks like
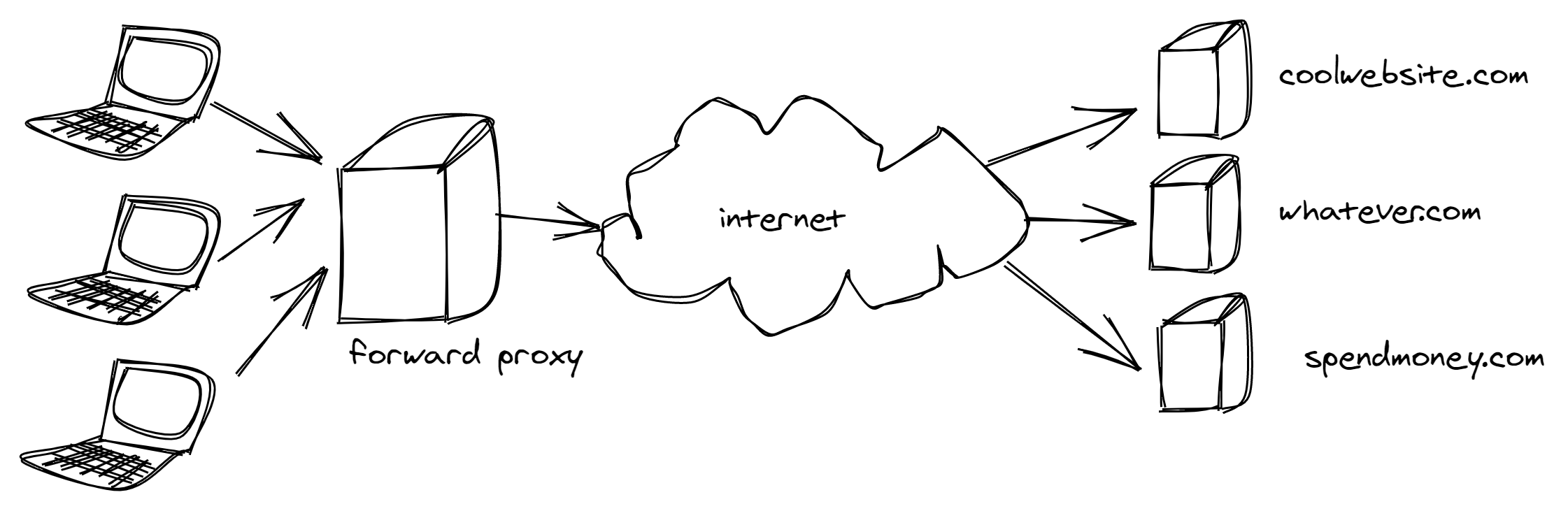
while a reverse proxy looks like this
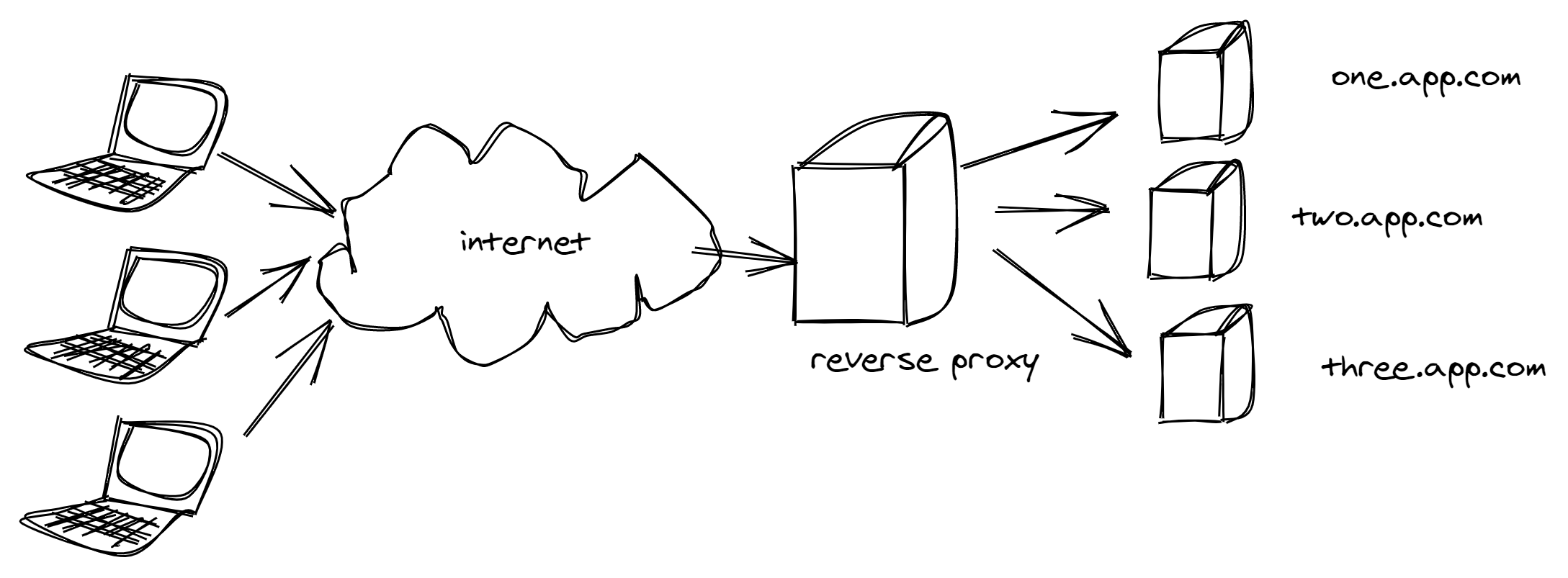
You get the idea, if it’s on the client-side of the network, it’s a forward proxy and if it’s on the server-side of the network, proxying requests for our apps, then it’s a reverse proxy.
Writing a Reverse Proxy in Go
I’ll try to build a very simple reverse proxy server using the net package, following this amazing talk by Filippo Valsorda. The net provides access to low-level networking primitives of the machine. The three methods under the net that I’ll be using are -
net.Listen()net.Accept()net.Dial()
We’ll start by writing a TCP listener that runs on 8000 and continuously accepts incoming connections, by using an infinite loop.
func main() {
l, err := net.Listen("tcp", "localhost:8000")
if err != nil {
log.Fatal(err)
}
for {
conn, err := l.Accept()
if err != nil {
log.Fatal(err)
}
}
}
Now that we are done with that, we need to proxy the requests to a server that’s running at, say, localhost:8001. Let’s add a method called proxy that does this job, and we can invoke this via a goroutine since we don’t want to be blocking other connections from other clients. So, our infinte loop block will have the proxy function call,
...
conn, err := l.Accept()
if err != nil {
log.Fatal(err)
}
go proxy(conn)
...
What does proxy function need to do?
The proxy function needs to
- Accept the
connfrom the client. - Connect to the upstream, in our case, it will be
localhost:8001, the server which we are proxying for. - Read data from the client and send it to upstream.
- Read data from the upstream and send it to the client.
- Close the connections on both ends once it’s done.
So we have,
func proxy(conn net.Conn) {
defer conn.Close()
upstream, err := net.Dial("tcp","localhost:8001")
if err != nil {
log.Print(err)
return
}
defer upstream.Close()
go io.Copy(upstream, conn)
io.Copy(conn, upstream)
}
It’s worth mentioning here why the first io.Copy is a goroutine while the second is not. We do not want to block copying response from the upstream to the client, until client has finished sending all the data to upstream. I’m highlighting the word finished here because in some cases, such as HTTP it may never happen as the client might not drop the connection. So if the “upstream to client” copy is blocked the because the “client to upstream” is blocking it, then it’s a sticky situation. So we let the client write to upstream in its own time, and whatever we recieve from upstream we send it to client immediately.
In the end, our code looks like,
package main
import (
"net"
"log"
"io"
)
func main() {
l, err := net.Listen("tcp", "localhost:8000")
if err != nil {
log.Fatal(err)
}
for {
conn, err := l.Accept()
if err != nil {
log.Fatal(err)
}
go proxy(conn)
}
}
func proxy(conn net.Conn) {
defer conn.Close()
upstream, err := net.Dial("tcp","localhost:8001")
if err != nil {
log.Print(err)
return
}
defer upstream.Close()
go io.Copy(upstream, conn)
io.Copy(conn, upstream)
}
So Let’s start a simple node server at 8001,
var http = require('http');
http.createServer(function (req, res) {
res.write('Hello from the app!');
res.end();
}).listen(8001);
If you open up the browser and connect to localhost:8000, you’ll get the response from the node server running at 8001.
Now, Writing a proper reverse proxy implementation is a fairly complicated business but Go already has the reverse proxy implementation under the httputils package, part of its rich standard library. Under it is the ReverseProxy struct, it is an HTTP Handler that takes an incoming request and sends it to another server, proxying the response back to the client. We can directly use this to write a simple proxy server by configuring the Director. The role of the “director” is to modify the incoming requests and send them to one of our apps that’s behind it.
package main
import (
"net/http"
"net/http/httputil"
"net/url"
"log"
)
func main() {
app_url, err := url.Parse("http://localhost:8001")
if err != nil {
panic(err)
}
director := func (r *http.Request) {
r.URL.Scheme = app_url.Scheme
r.URL.Host = app_url.Host
}
proxy := &httputil.ReverseProxy{Director: director}
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
proxy.ServeHTTP(w, r)
})
log.Fatal(http.ListenAndServe(":8000", nil))
}
Again, this is a very simple proxy server that proxies incoming requests from the localhost:8000 to the app running at localhost:8001. If we now visit localhost:8000 we should get the Hello from the app! message from the node server.
X-Forwarded-Host
To identify the original Host that requested on behalf of the user, we can pass the X-Forwarded-Host. In a long chain of proxies, it can be useful to know the original Host. This stackoverflow thread has some interesting real-life uses of X-Forwarded-Host.
Just adding this extra line in the director function will now pass the Host along the proxy chain.
r.Header.Add("X-Forwarded-Host", r.Host)