Choosing between Python threads vs coroutines vs processes
For the last two months in quarantine, I have been playing this game called “State of Decay”. It’s a pretty decent game; made of the zombie-surviving base-building weapon-toting flu-denying elements, just so you know it’s a perfect crème de la crème pick of titles for these near apocalyptical times. Anyways, the game revolves around establishing a base in a town, recruiting survivors, and generally trying not to die from incoming hordes of zombies or starvation. So one major caveat of this game is that if a character dies in-game, you can never get them back. That’s it. they are gone, just like in real life. The game is set to auto-save, so there are no “let-me-go-back-and-fix-this-real-quick” moves. Sounds pretty fun right?
No.
To keep this intro short, I had a character called Maya, who was an expert at shooting (sweet military background), scavenging expert, a 4-star leader, and a pretty okay builder, so an overall top-notch post-apocalyptic survivalist. Also, there are these things called Juggernauts aka Jugs, huge zombies that hit like a train. So, I playing Maya, tried to loot a cache of food, met a Jug, and decided to fight it. Here’s a quick comic I drew that shows how it went down.
Lessons learned - do not fight jug with a bat, run when your weapon breaks, and always take backups even if the game doesn’t allow you to. So I had to write up quick tool that would allow me to archive the game’s save directory with timestamps every 10 mins and store it somewhere in my filesystem. It was a very rudimentary desktop application with python and very minimal GUI.
So in essence, There were main logical components of the program - a loop that took backups and a listener that listened for user inputs like stop or start from the GUI. At that time, the quick solution was to use a thread, which would be non-blocking, and would listen to the user inputs while the main thread concentrated on getting the backups. Was it efficient of threads? No. But at that time, I promised myself I’ll take a look at the problem later.
Understanding Processes
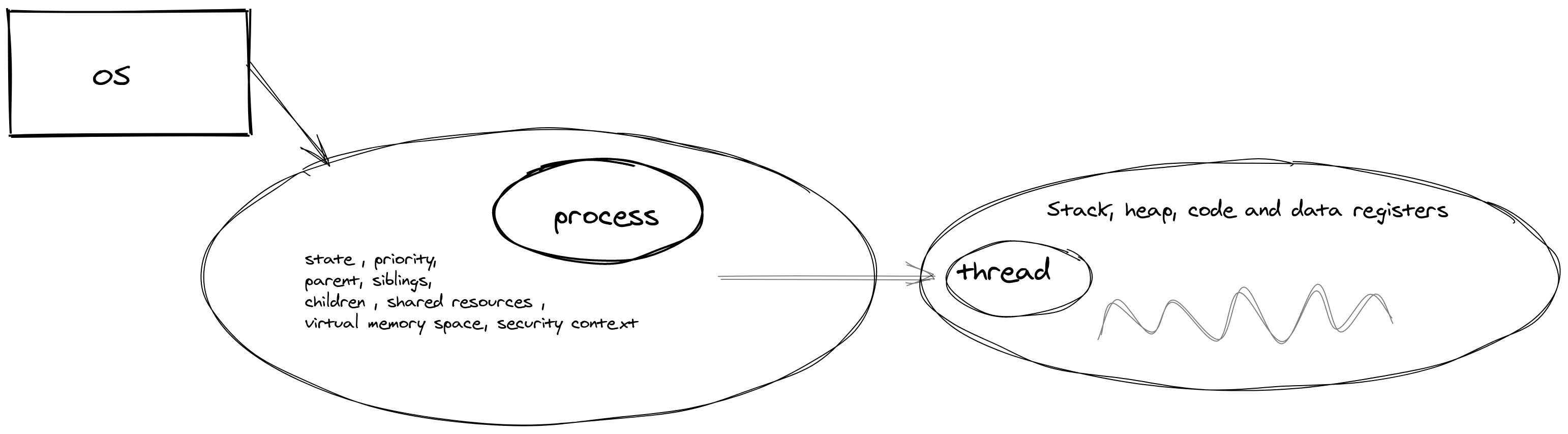
When you start a python process, eg. python main.py, the operating system allocates a bunch of things based on the invocation, such as state, priority, parent and siblings, shared resources (files, pipes & sockets) and virtual memory space. Also, every process is created by another process, in this case, the python process is created by the main system process. Why do we need to understand this? because it helps us identify where threads lie in the order of things.
Processes are at the top level, they are independent and they have separate address spaces and PIDs. Also, communication between them is determined by IPC (inter-process communication). The CPU runs multiple parallel processes by using what is called context switching. Let’s imagine them as if the CPU juggles between the processes.
Now each process can create its threads. From Computer Sci 101, we know that a program has like 4 main segments - Stack, Data, Code, and Heap. Threads, since they are created by a process, share all of them except the Stack. Also, Threads within a process can interact with each other by accessing each other’s stack. So there is significantly less overhead in moving between thread to thread.
From our understanding of the above, context switching between Process is costlier that context switching between threads.
What about Concurrency?
Threads and processes aren’t the only way of making a program do multiple things. We can make use of the switching within a single thread to work on multiple tasks. This is the core idea behind the event loop. The programmer can tell the program to switch “context” to another task if some task is taking too much CPU idle time and Python allows us to do that via the asyncio module. There is a great talk by David Beazley, where he builds concurrency from the ground up like a wizard on stage.
Since there is just one thread, or an event loop thread if you will, the memory overhead is low. Also, if you can identify the slowest parts of your program, like waiting for some file to read or API calls, you can use the idle wait time to do something else and make the CPU work like it owes you money. A popular candidate in async programming space in NodeJS, JS devs are used to async nature from the get-go and now Python has the async sauce, straight out the NodeJS playbook.
So if it’s making the best use of my CPU and has less memory overhead, I should write all my python in async await syntax, right?
The Test
I’m going to branch off from Beazley’s idea in his talk and try to see if I can measure a bunch of things, so that next time I need to build a save manager-script or something like that, I can make sure that I don’t write crap.
As always, let’s build a TCP server using threads in python.
import socket
import threading
def sometask():
return "hello world"
def server(address):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(address)
sock.listen(5)
while True:
client, addr = sock.accept()
print("connection from ", addr)
th = threading.Thread(target=handler, args=(client, ))
th.start()
def handler(client):
while True:
req = client.recv(100)
if not req:
break
res = sometask()
resp = str(res).encode('ascii') + b'\n'
client.send(resp)
print("req closed")
server( ("localhost", 8000) )
This server does one thing, if you nc localhost 8000 and type in anything, it’s going to spit out “hello world”. The request-response cycle is so fast, we can put the stress on the program. The performance of request-response will be bottlenecked by the threads, allowing us to approximately measure it.
Let’s quickly write up that performance script just as Beazley did. This will hammer the server with a ton of requests and we’ll be able to measure the maximum amount of requests that the server can handle per second.
#perf file
import socket
import threading
import time
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect( ("localhost", 8000) )
n = 0
def printReqRate():
global n
while True:
time.sleep(1)
print(n)
n = 0
counter = threading.Thread(target=printReqRate)
counter.start()
while True:
sock.send(b'1')
resp = sock.recv(100)
n += 1
If we start the server and run it, we can start measuring the request rate.
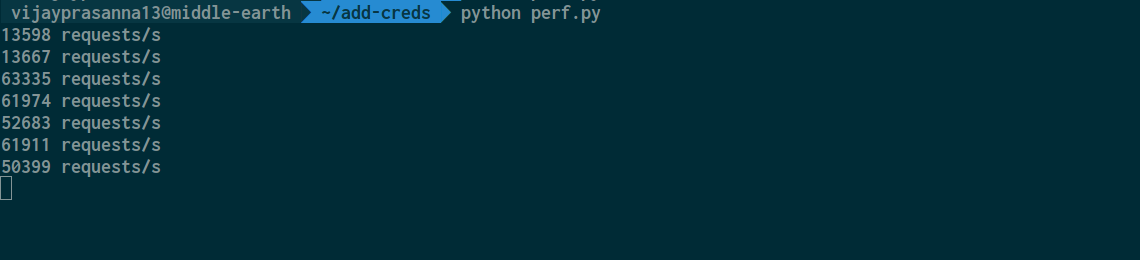
Notice the request rate after another client is added. The requested rate almost halves. I am going to go ahead and add a bunch of more clients and watch the trend of the request rate and track memory and the CPU as well.
The trend of the request rate as I gradually go from 0 clients to 4 clients.
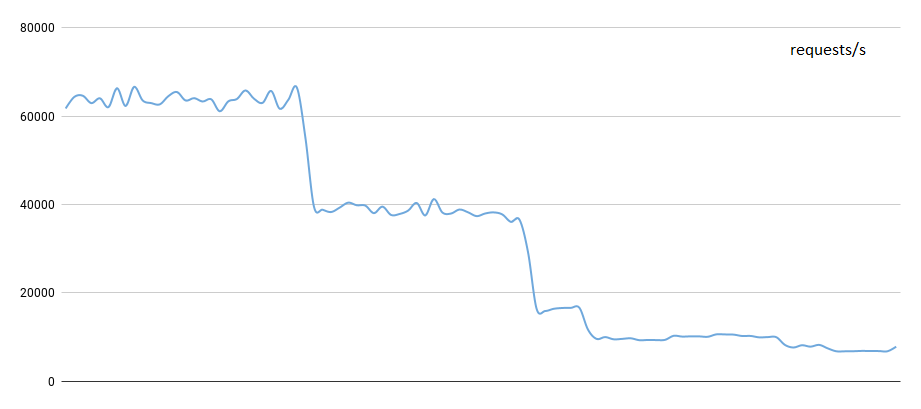
As expected, the request rate goes down by half of itself every time a new client is added. It goes from ~60k req/s to 40k req/s to 20k req/s to 15k req/s. So this gives a general idea of how thread-based programs react to the addition of new clients who are very active.
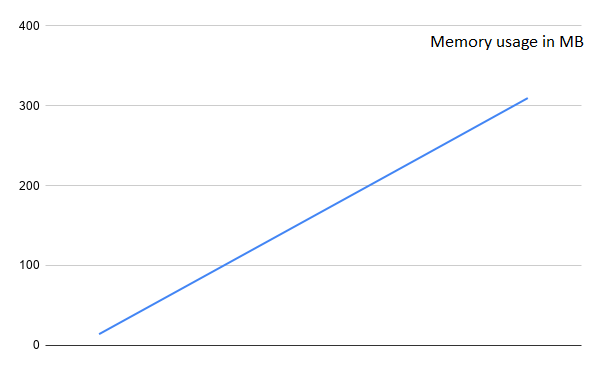
Quickly mapping out the memory and seeing how it fared across the whole trip.
We can see it increased linearly the whole time. starting from 14 MB then growing to almost 300 MB. It’s not really memory efficient but it’s not too bad either.
Let’s try the same thing on an async-await based server.
import socket
import asyncio
def sometask():
return "hello world"
async def run_server():
while True:
client, addr = await loop.sock_accept(sock)
print("connection from ", addr)
loop.create_task(handler(client))
async def handler(client):
while True:
req = int(await loop.sock_recv(client, 255))
if not req:
break
res = sometask()
print(req, res)
resp = str(res).encode('ascii') + b'\n'
await loop.sock_sendall(client, resp)
print("req closed")
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(("localhost", 8000 ))
sock.listen(5)
sock.setblocking(False)
loop = asyncio.get_event_loop()
loop.run_until_complete(run_server())
We have to convert the socket functions into the async objects offered by the asyncio library for socket-based primitives. Running the same test again, we get:
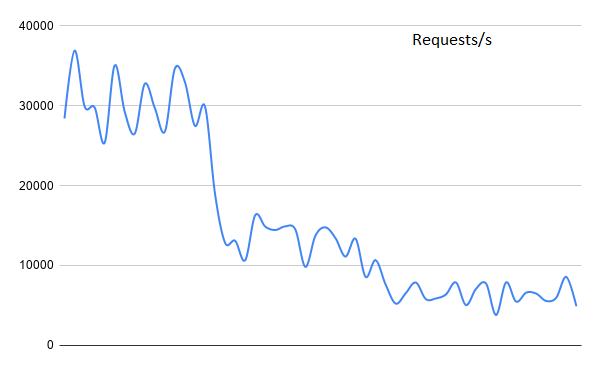
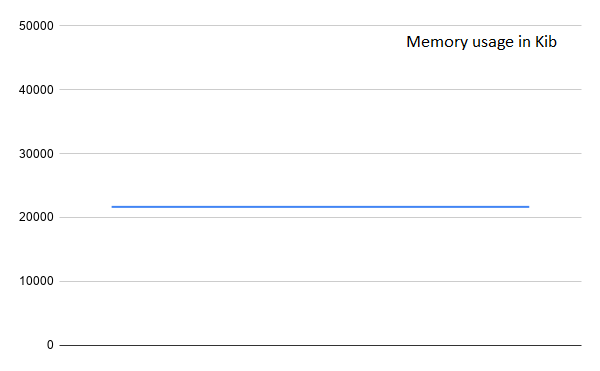
We can see that not only is the reqs/s lower than a thread-based server, it’s also wacky as heck. This is the CPU trying to catch and handle clients whenever it gets the time to do so. Note that we are not the only ones using the CPU, other system processes are doing it as well. A good part of this is the memory usage, it stays at 21 MB flat, which is expected since the event loop is running the whole show.
CPU Usage
This is ps aux output from the threaded server test. Notice the PSR is 2, which refers to the CPU core the process is running on.
| PID | PSR | COMMAND |
|-------|-----|---------|
| 49188 | 2 | python |
This is from the second test:
| PID | PSR | COMMAND |
|-------|-----|---------|
| 48978 | 1 | python |
Throughout the whole test, the server - despite being run with the help of threads it never utilized the full power of the CPU. At all times, the python was locked onto one core of the machine. This can be attributed to the GIL (Global Interpreter Lock) of CPython, which probably what most people use.
Utilise multiple CPU cores from a single python program
Like we discussed in the beginning, the Operating system allocates process onto a CPU core, so if we can spawn python processes from the program instead of threads, then technically we should be able to run each “client” as a separate process, on different CPU cores. I am running my tests on a 4 core machine, which by utilising Intel hyperthreading should translate to 8 virtual cores.
So, let’s modify the server code, to spawn a process instead of a thread for an incoming connection.
import socket
from concurrent.futures import ProcessPoolExecutor
def sometask():
return "hello-world"
def server(address):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(address)
sock.listen(5)
while True:
client, addr = sock.accept()
print("connection from ", addr)
executor.submit(handler, client)
def handler(client):
while True:
req = client.recv(100)
if not req:
break
res = sometask()
resp = str(res).encode('ascii') + b'\n'
client.send(resp)
print("req closed")
executor = ProcessPoolExecutor(4)
server( ("localhost", 8000) )
I have allocated for 4 process threads for the program, and if we run this now:
| PID | PSR | COMMAND |
|-------|-----|---------|
| 49371 | 1 | python | <- main thread
| 49648 | 1 | python | <- process 1 is running on core 1
| 49649 | 5 | python | <- process 2 is running on core 5
| 49650 | 2 | python | <- process 3 is running on core 2
| 49651 | 3 | python | <- process 4 is running on core 3
Let’s measure the performance of the server while we are at it:
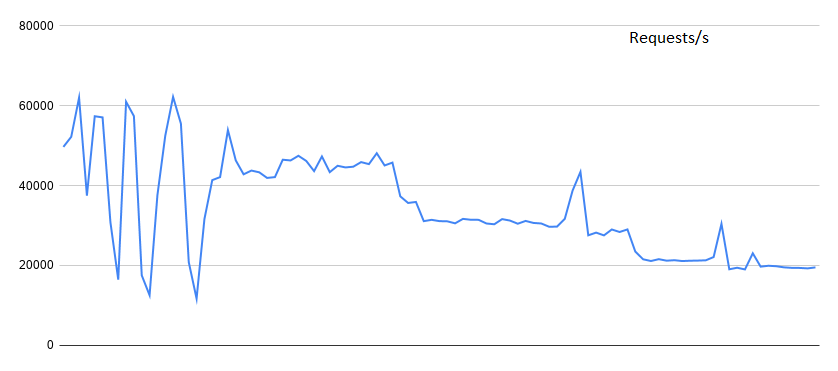
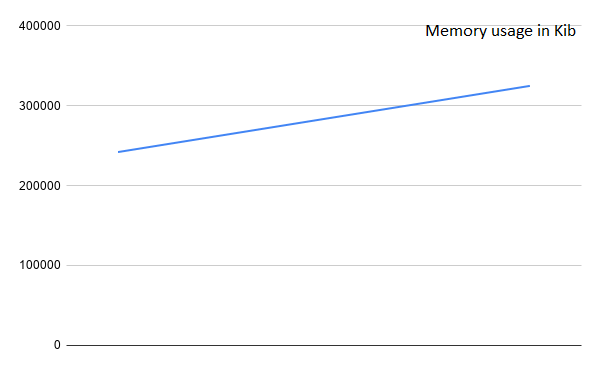
Req/s is really good here, on adding one client after another. It starts very high, at 60k req/s, just like the threaded case, but the dip in req/s is very slow, and barely goes below 20k even after adding 4 clients. But memory-wise, there is a significant overhead since each process has to be allocated its v-memory amongst other things.
So what now?
We can see the tradeoffs between 3 different approaches, and like all things, the answer is - it depends. It depends on your hardware and what your use cases are. If you want to run a resource-intensive task, then spawn a process to do that so that the CPU can concentrate on that task, while your client requests are handled by threads. If you are running a webserver for, say, a chat application, an asyncio might help you there. If I go back to my backup script, looking at the results here, I would probably pick asyncio, since it’s a very small task and there is no real need to hog memory just to listen to user inputs.